
Each node may have an arbitrary number of labels, denoted by a leading colon; for example, nodes p1, p2 and p3 all have the label :Product. Node labels are optional, i.e. there may be unlabeled nodes.
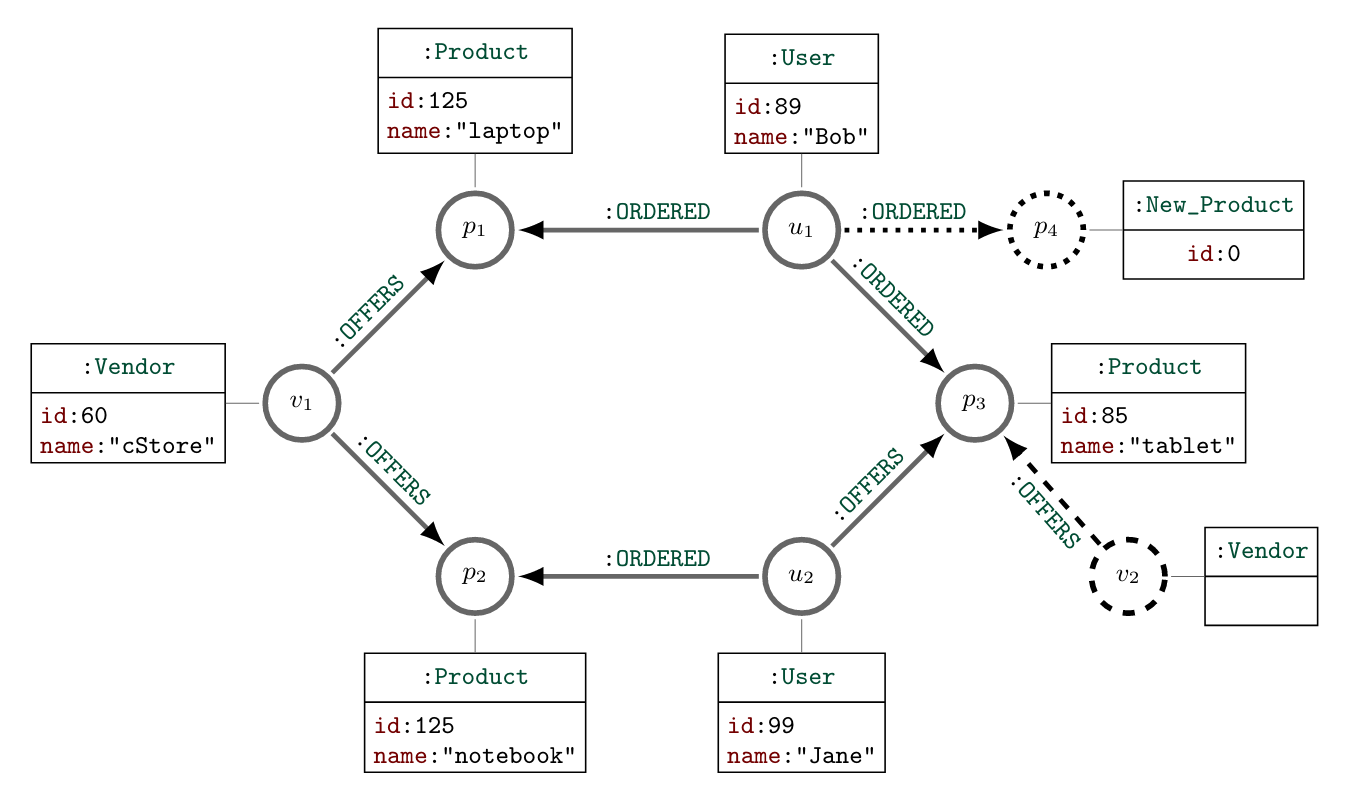
Figure 1: Property graph for the running examples of Sections 2 and 3. Solid lines indicate the initial graph; dotted lines the additions from Query 1; dashed lines – the additions from Query 4.
Each relationship has precisely one source node, target node, and type, with the latter denoted by a colon; for instance, the relationship between nodes u1 and p1 is of type :ORDERED. The uniqueness of source and target nodes means that relationships are always directed from source to target, and there may never be any “dangling relationships” (i.e. relationships with a missing source or target). There may, however, be multiple relationships with identical types and properties between the same nodes.
Both nodes and relationships may have an optional property map, given as a set of key-value pairs. In the example, all nodes have id and name properties, while relationships do not have any properties; in general, property keys can also vary between nodes (or relationships, respectively).
~
GREEN, Alastair, GUAGLIARDO, Paolo, LIBKIN, Leonid, LINDAAKER, Tobias, MARSAULT, Victor, PLANTIKOW, Stefan, SCHUSTER, Martin, SELMER, Petra and VOIGT, Hannes, 2019. Updating graph databases with Cypher. Proceedings of the VLDB Endowment. August 2019. Vol. 12, no. 12, p. 2242–2254. doi ![]() . pdf
. pdf ![]()
The paper describes the present and the future of graph updates in Cypher, the language of the Neo4j property graph database and several other products. Update features include those with clear analogs in relational databases, as well as those that do not correspond to any relational operators. Moreover, unlike SQL, Cypher updates can be arbitrarily intertwined with querying clauses. After presenting the current state of update features, we point out their shortcomings, most notably violations of atomicity and non-deterministic behavior of updates. These have not been previously known in the Cypher community. We then describe the industry-academia collaboration on designing a revised set of Cypher update operations. Based on discovered shortcomings of update features, a number of possible solutions were devised. They were presented to key Cypher users, who were given the opportunity to comment on how update features are used in real life, and on their preferences for proposed fixes. As the result of the consultation, a new set of update operations for Cypher were designed. Those led to a streamlined syntax, and eliminated the unexpected and problematic behavior that original Cypher updates exhibited.
[…] Unlike many other languages that are defined by means of a specification in natural language, the read-only core of Cypher has been fully formalized [13, 12], […]
[12] N. Francis, A. Green, P. Guagliardo, L. Libkin, T. Lindaaker, V. Marsault, S. Plantikow, M. Rydberg, M. Schuster, P. Selmer, and A. Taylor. Formal semantics of the language Cypher. CoRR, abs/1802.09984, 2018. arxiv ![]() .
.
[13] N. Francis, A. Green, P. Guagliardo, L. Libkin, T. Lindaaker, V. Marsault, S. Plantikow, M. Rydberg, P. Selmer, and A. Taylor. Cypher: An evolving query language for property graphs. In Proceedings of the 2018 International Conference on Management of Data, SIGMOD ’18, pages 1433–1445. ACM, 2018.