
A good way to understand the federation is to write a sitemap scraper. matrix ![]()
I wrote a scraper once that was a lot of fun to watch as it was written in one html script tag that animated the scrape as it went. I never distributed it because no learning comes from running it, just a lot of fetch load on the federation. I would share it with anyone who promised to run it only once and then destroy it.
Tip to self: it is called scrape-pages.html. Try sys/find.
I found a copy on a remote disk. I opened the html file in chrome which launched the scrape. Within seconds it had filled my screen with info gleaned from sitemaps.
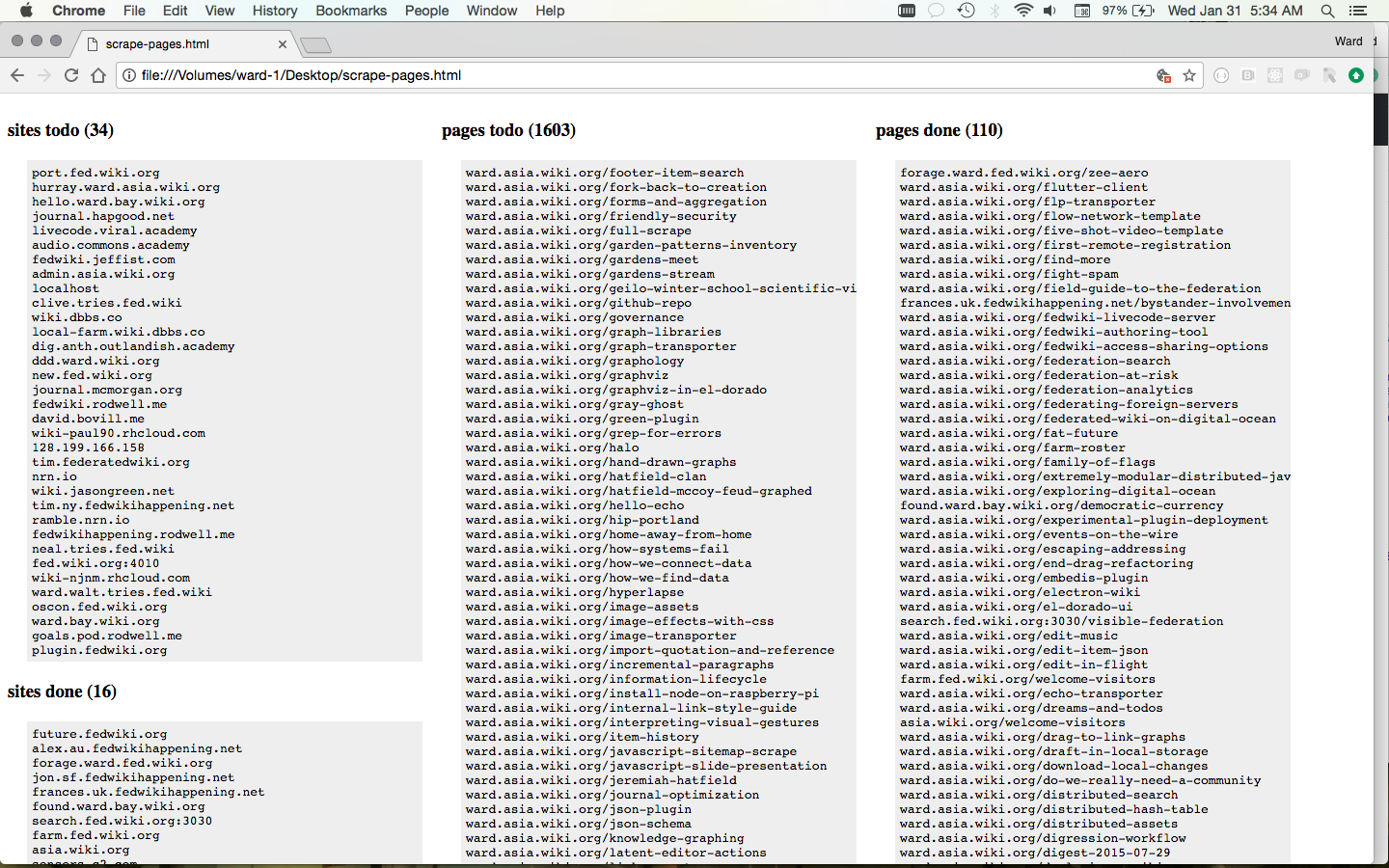
Now, after 35 minutes of scraping, and stopping a few times, we have found a lot more work to do.
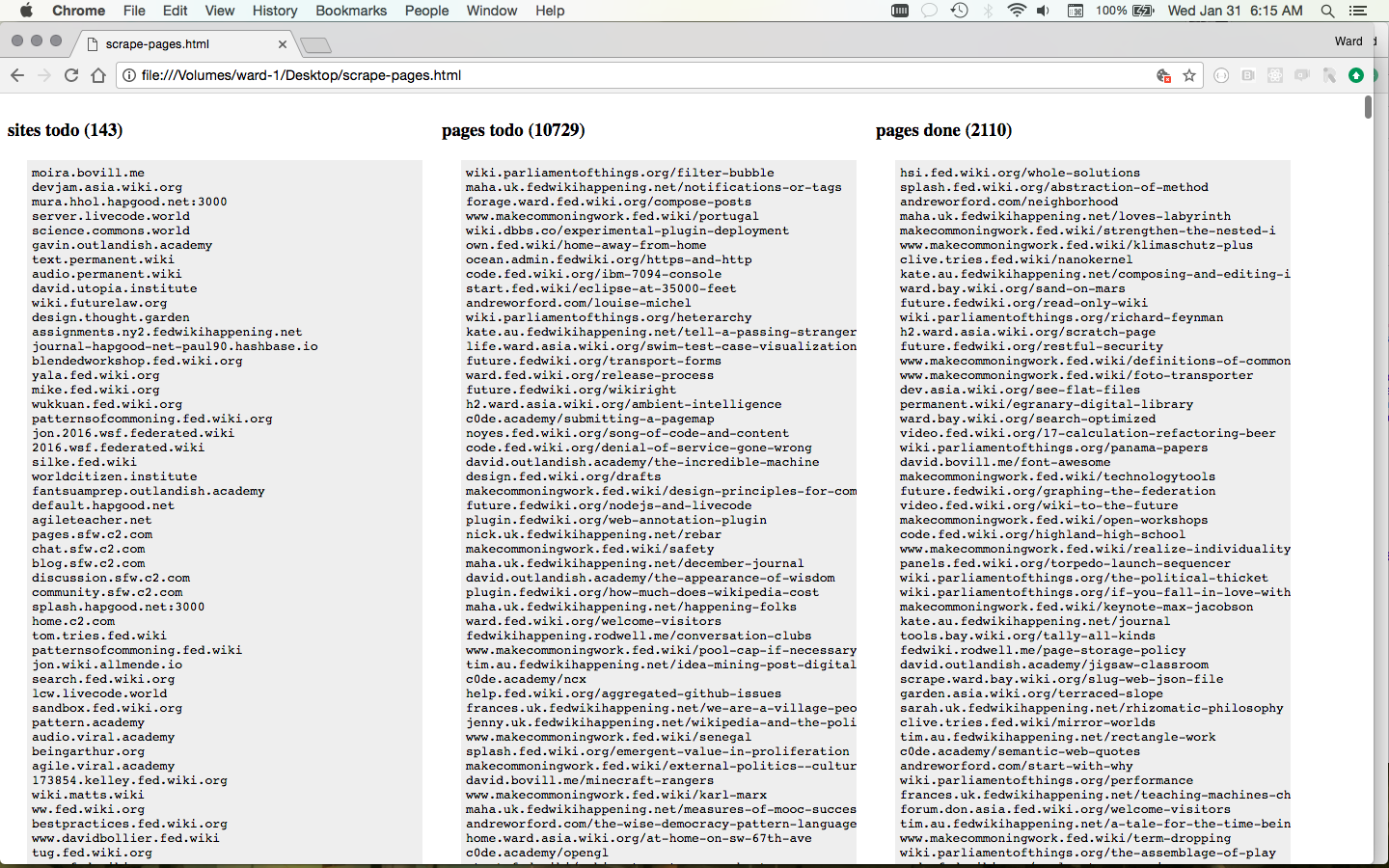
This script is fetching every reachable page. My four-times daily scrape that feeds search only fetches pages that have changed in the last six hours. This is much less abusive of sites. See How Scrape Works
I make scrape data available in several formats and update this four times a day. See Search Index Download
# Code
Here are a few javascript snippets to give you an idea how sitemaps guide a scrape.
As we visit each site we add its pages to that todo list.
function do_site(site, sitemap) { for (var i=0; i<sitemap.length; i++) { try { var entry = sitemap[i]; if (entry.date > oldest) { var site_page = site + '/' + entry.slug if (new_page(site_page)) { pages_todo.push(site_page) } } } catch (e) { } } pages_todo.sort(chronological); }
As we visit each page we add new sites to that todo list.
function do_page(site, slug, page) { try { for (var i=0; i<page.story.length; i++) { var item = page.story[i] if (item.site && new_site(item.site)) { sites_todo.push(item.site) } } for (var i=0; i<page.journal.length; i++) { var action = page.journal[i] if (action.site && new_site(action.site)) { sites_todo.push(action.site) } } } catch (e) { } }